Introduction
A variety of issues around AI have come to occupy our societal consciousness: Can AI ever become sentient? Is the singularity possible, and if so, how far away is it? How will AI reshape labor, relationships, education, and creative endeavors? Below the news cycles and headlines, there is a subtle undercurrent of challenges that practitioners and policy makers are grappling with. While the issues on the distant horizon are worth discussing in depth, the battles lying below the surface are being fought right now. If ethicists, philosophers, and theologians cannot lend a voice to subtle contemporary challenges now, it will be difficult to alter the direction of future discourse once legal and social precedents have been set. The debate around perceptual hashing is one such issue that demands greater attention.
Perceptual hashing lies at an interdisciplinary crossroads of AI and cryptography. Since its inception, advances in cryptography (securely encrypting and decrypting messages) have always been accompanied by advances in cryptanalysis (undermining those same encryption and decryption schemes). AI has become more like cryptography in this sense: with each new model advancement, adversarial machine learning models are designed to undermine them.
First, this piece offers a brief introduction of both cryptographic and perceptual hashing methods. We then describe some advertised benefits of perceptual hashing, as well as ways it could be abused by companies, governments, and individuals. Hopefully a deeper understanding of the technology and the risks governing it will help ethicists weigh in as policies are crafted and laws are passed to adequately control this domain.
Cryptographic Hashing
Before exploring perceptual hashes, let us consider a standard cryptographic hash function. For a variety of reasons, developers often need to take blobs of arbitrary data (varying in size, type, content, etc.) and map them to a unique, fixed-length set of characters known as a hash. Any such mapping is known as a hash function. Hash functions are extremely efficient algorithms for creating such mappings. Hashes do not resemble the initial data. Similar inputs do not produce similar hashes (but identical inputs produce identical hashes), and mapping a hash back to the initial data is, by design, practically impossible1. For example, take the hash function SHA256. Figure 1 shows a few examples of SHA256 in action.
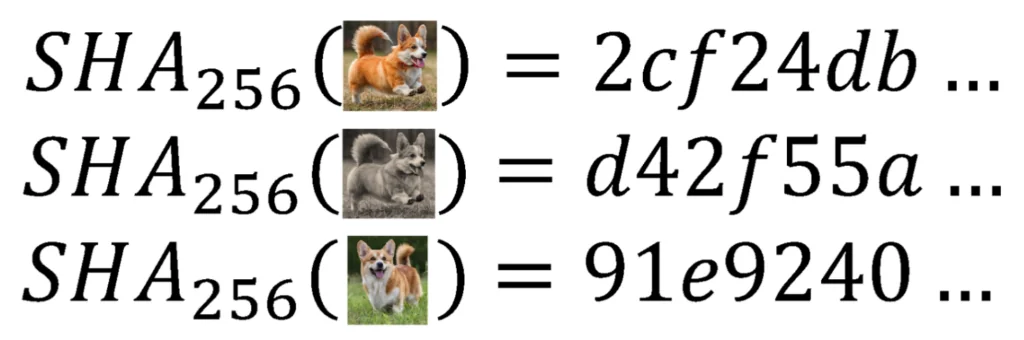
Figure 1: An example of SHA256 hashes on three images. Any apparent similarity between hashes is coincidental.
Hash functions are used routinely for password, message, and file verification. For example, a company that stores client passwords in a cleartext file is vulnerable to a massive security breach if the password file is ever compromised. Instead, suppose a hash is stored for each client. The client can type their password, hash it, and send the hashed password to be compared with the stored hash. If the two hashes match, then the authentication is successful. If the stored hashes are ever compromised, the attackers cannot determine the client’s original password.
Perceptual Hashing
Suppose a developer wants to rapidly determine if an exact search image is present in a database. Rather than executing an expensive operation of comparing the pixels of each image to the search image, a less intensive approach would rely on comparing the hash of the search image to the hashes of the images in the database. But what if the developer wants to identify images that are a close but inexact match? For example, perhaps the search image is slightly cropped or recolored. As we showed previously, a cryptographic hash cannot help with similar matches, only exact matches. Perceptual hashes, unlike cryptographic hashes, capture information on the similarity between images2 3. Figure 2 shows the same examples on the images above, but using a perceptual hash.
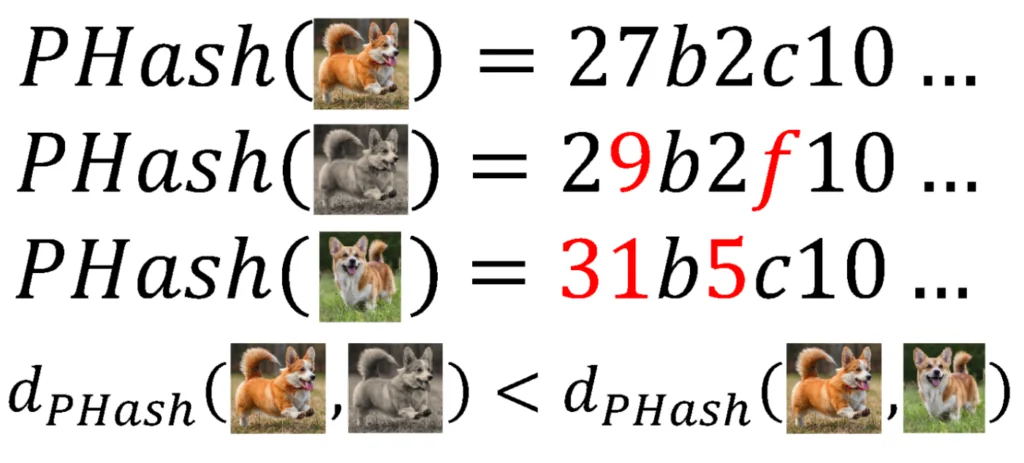
Figure 2: An example of perceptual hashes on three images. The similarity between the hashes is related to how similar the images are.
Perceptual hashing is typically accomplished using a deep learning approach known as a variational autoencoder (VAE). VAEs are composed of three main components: an encoder, a latent representation, and a decoder. Put simply, a VAE is trained on a dataset (say, of images) by passing an image through the encoder to get a latent representation (typically a vector of numbers), then passing that latent representation through a decoder to get an image back out. If a developer is only interested in the perceptual hash, the encoder can yield latent representations quite efficiently and the decoder can be discarded (although the decoder is still required for training). This perceptual hash can uniquely represent an image while maintaining some content-aware capabilities that allow for similar images to be mapped nearby.
Benefits of Perceptual Hashing
Perceptual hashes are one of the most common tools for client-side scanning, which has been universally adopted by several major tech companies. The most cited use case is to prevent the dissemination of child sexual abuse materials (CSAM), and works as follows. When someone captures an image on a device, a fully transparent VAE encoder on the device creates a perceptual hash of the image. Before the image is shared with anyone, say via a messaging app with end-to-end encryption, the perceptual hash is passed to a secure location where it can be quickly compared to a list of banned perceptual hashes. If the captured image hash is not close to a banned hash, then the image is shared. However, if the captured image hash is close to a banned hash, the image is not shared. Figure 3 shows a diagram of this process. The policy on what happens to the user and their device afterward varies. In some cases, the user is warned of potentially explicit content before verifying that they want to send the image anyway. In other cases, a user may find themselves locked out of their devices and accounts4.
Proponents of client-side screening point out that perceptual hashing enables devices to, in a sense, police their users. For years, law enforcement agencies have repeatedly sought to force companies to provide “back door access” to devices, which companies have been reticent to do5. Perceptual hashing is seen by many as a less invasive alternative6. Finally, perceptual hashing clearly limits the dissemination of CSAM, and any useful method capable of limiting its spread deserves our careful consideration7.
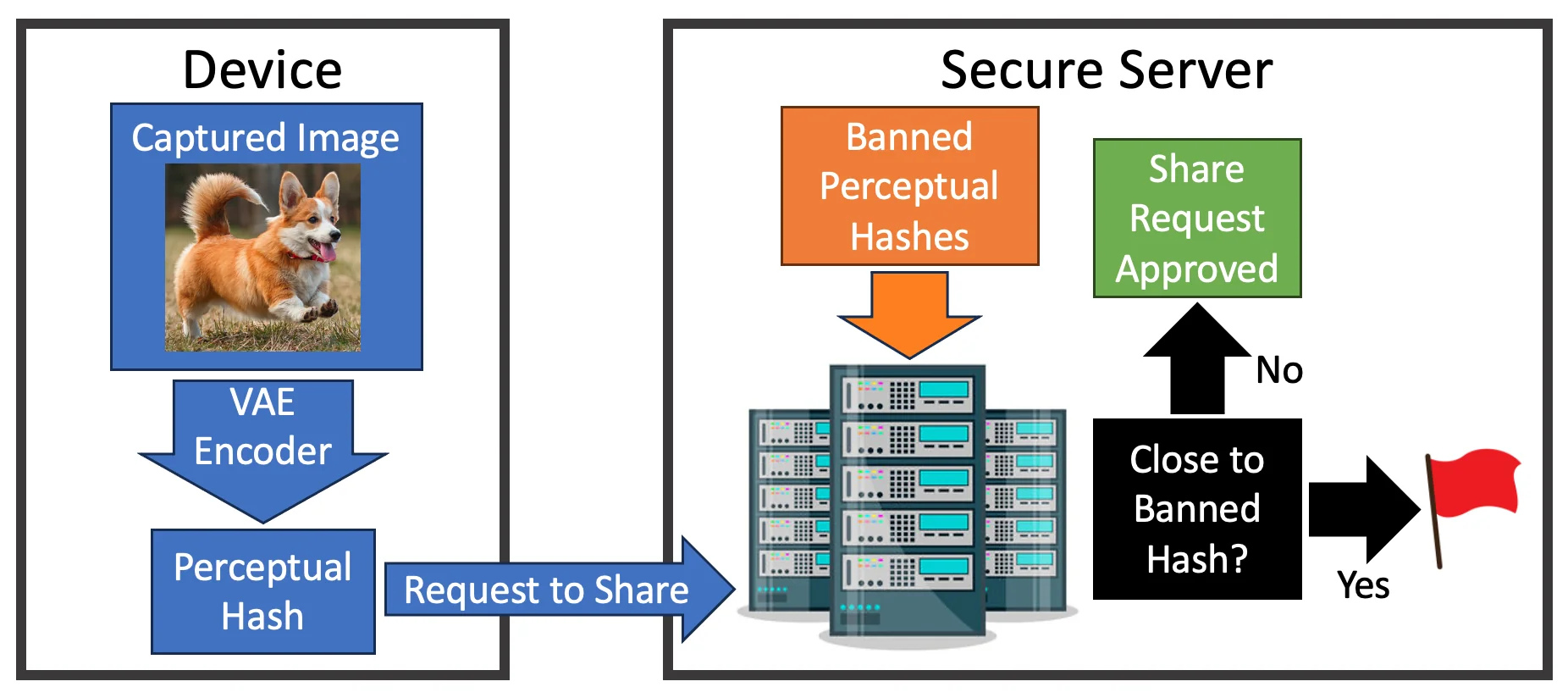
Figure 3: Determining whether an image can be sent based on its perceptual hash.
Downsides of Perceptual Hashing
While major tech companies still employ perceptual hashing on their devices, several deficiencies have since been identified. For example, in 2021 (amidst the COVID-19 pandemic and resultant proliferation of telehealthcare) a concerned father used an Android phone to send an image of his son’s genitals to a telehealth provider for medical diagnostic purposes. Subsequently, the parent’s phone that transmitted the image could not be unlocked and he was unable to access his Google account8. It has proven nearly impossible to differentiate CSAM from images captured for medical purposes. In addition to stories of “false positives”, Struppek et al. also documented incidences of “false negatives” where an image that should have been detected for containing CSAM is not flagged9. Furthermore, a bad actor who wishes to bypass the perceptual hashing process can still send an image via certain applications.
Aside from the troubles of an imperfect model, the reality is that governments are currently vying to use perceptual hashing for surveillance and censorship. Under the guise of preventing CSAM, governments could easily force companies to expand the set of banned hashes. This measure would effectively grant a government the power to track or prevent the spread any images they would like to suppress10 11; oppressive regimes are likely already using this approach.
Another issue with perceptual hashes is their potential invertibility, such that someone could recover the image being sent based on its hashed value. Apple’s NeuralHash perceptual hashing code is available here, and anyone can hash any images they wish. But because perceptual hashes are initially trained with a decoder and thus contain some information about the original image content, developers have already found ways to reverse-engineer this decoder. So, for any image being shared, a man-in-the-middle attack could identify perceptual hashes and determine the images being shared. Furthermore, if the list of banned hashes were ever leaked, users could feasibly decode these banned hashes back to content approximating the original CSAM.
Finally, some adversarial methods that could enable bad actors to use perceptual hashing as a form of doxing. There is a common strategy in adversarial machine learning that involves adding carefully crafted noise to an image so that a neural network is incapable of correctly identifying the image content12. In this case, a bad actor could start with an innocuous image and add noise so that, while the image still appears innocuous to the human eye, it would be flagged by the machine’s perceptual hashing routine as CSAM. Suppose the bad actor could get this image onto a target’s device: If the target attempts to share this image, their device may be locked and their accounts rendered irretrievable.
While perceptual hashing may appear beneficial in stemming the spread of CSAM, the approaches being implemented by large tech companies come with a few troubling social, technical, and ethical ramifications.
Conclusion
The fields of AI and machine learning are moving very quickly, and ethicists will face many challenges as they navigate this budding space. In addition to important questions about the future of work and education considering novel AI tools, the benefits and dangers of perceptual hashing could easily go unnoticed. Hopefully, a clearer understanding of the technology and its inherent risks aids ethicists and policy makers to carefully weigh these tradeoffs.
Acknowledgements
This piece is dedicated to Prof. Ross Anderson, who passed away unexpectedly on March 28, 2024. Prof. Anderson was a professor at the University of Cambridge and was a giant in the fields of computer security, cryptography, dependability, and technology policy. His writings on perceptual hashing significantly influenced this piece. Ross was known for standing up for what he believed in even when doing so proved inconvenient, even costly. He will be sorely missed. May he rest in peace.
Views and opinions expressed by authors and editors are their own and do not necessarily reflect the view of AI and Faith or any of its leadership.
